
“Broadly accessible machine translation systems support around 130 languages; our goal is to bring this number up to 200,” the authors write as their mission statement. NLLB Team et al. 2022
Meta Properties, owner of Facebook, Instagram and WhatsApp, on Wednesday unveiled its latest effort in machine translation, a 190-page opus describing how it has used deep learning forms of neural nets to double state-of-the-art translation for languages to 202 languages, many of them so-called “low resource” languages such as West Central Oromo, a language of the Oromia state of Ethiopia, Tamasheq, spoken in Algeria and several other parts of Northern Africa, and Waray, the language of the Waray people of the Philippines.
The report by a team of researchers at Meta, along with scholars at UC Berkeley and Johns Hopkins, “No Language Left Behind: Scaling Human-Centered Machine Translation,” is posted on Facebook’s AI research Web site, along with a companion blog post, and both should be required reading for the rich detail on the matter.
“Broadly accessible machine translation systems support around 130 languages; our goal is to bring this number up to 200,” they write as their mission statement.
For the simple view, check out ZDNet‘s Stephanie Condon’s overview report. As Stephanie relates, Meta is open-sourcing its data sets and neural network model code on GitHub, and also offering $200,000 I’m awards to outside uses of the technology. The company partnered with Wikipedia’s owners, the Wikimedia Foundation, to bring improved translation to Wikipedia articles.
Also: Meta’s latest AI model will make content available in hundreds of languages
A surprise buried in the report is that despite a measurable improvement across the board on a larger group of languages, as indicated by automatic scoring systems, when it comes to human evaluation on the quality of translations, the researchers’ neural net, known affectionately as “No Language Left Behind Two Hundred,” or NLLB-200, fails to show much improvement in a number of language cases, including not only low-resource languages such as Oromo but also languages with prevalent translation material such as Greek and Icelandic.
The lesson is that despite an ability to bring up average scores, the intricacies of creating translations that are meaningful, at least as far as a human views the translation, can not simply be automated. The authors found where they made their numeral net bigger, which should mean more powerful, they actually found diminishing returns when translating sentences from English to another language, and some negative effects when translating between non-English sentences.
The team took many steps to improve translation, including interviewing hundreds of native speakers of low-resource languages — interviews last an hour and a half, on average — to assess needs and concerns of speakers. (There is extensive discussion of the ethics of such field work and the ethics of incorporating low-resource languages that could be overwhelmed by a flood of attention; that discussion in the paper bears special attention.)
Also: Google’s massive language translation work identifies where it goofs up
But the heart of the work is their having gone to great lengths to compile a new data set to train their neural network, even inventing new methods — which they offer as source code — to perform language identification on Web materials, to identify which tests belong to a language.
They use automated methods to compile a data set of bilingual sentence pairs for all their target languages. The data set has some pretty thrilling statistics:
In total, there are 1220 language pairs or 2440 directions (xx-yy and yy-xx) for training. These 2440 directions sum to over 18 billion total sentence pairs […] the majority of the pairs have fewer than 1M sentences and are low-resource direction.
The authors use that data to train the NLLB neural net, but they also a hand-crafted data set of translations built by human translators. The human element, the “NLLB-SEED” data set, turns out to be pretty important. “Despite the considerably larger size of publicly available training data, training on NLLB-Seed leads to markedly higher performance on average,” they write.
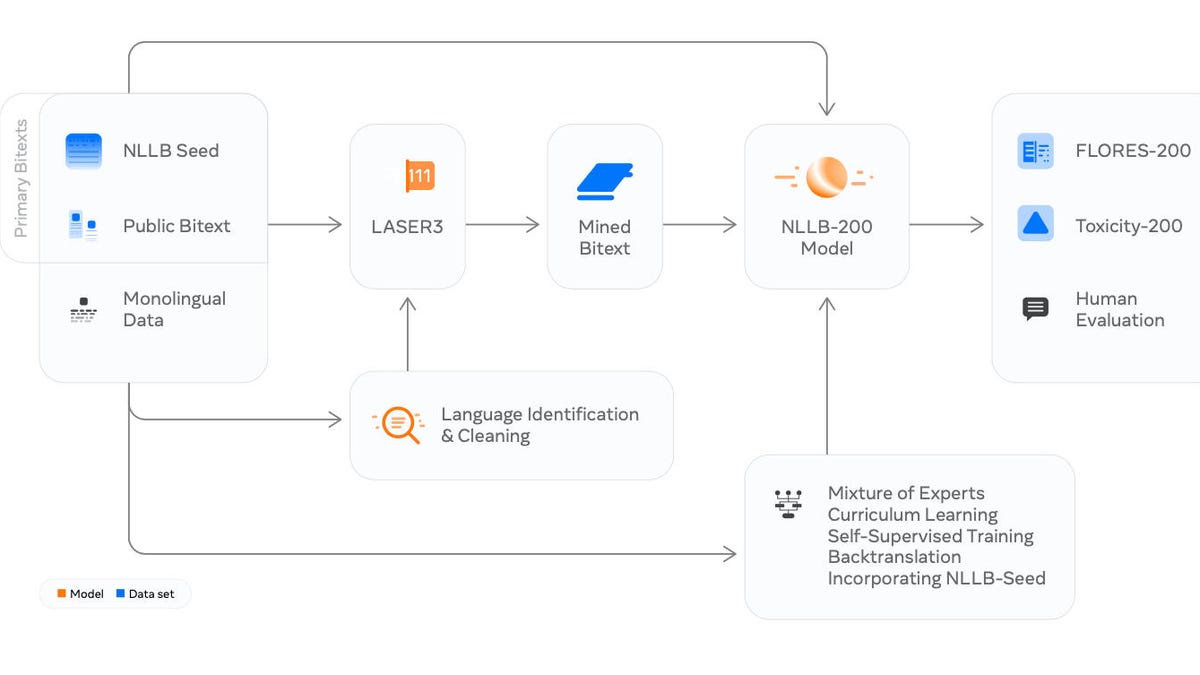
The NLLB effort includes multiple steps, starting with scouring publicly available bidirectional texts of language pairs, identifying the langauges via automated methods, creating a giant training data set, training the NLLB-200 neural net, and then evaluating the program on a new benchmark data set created with human translators, FLORES-200. NLLB Team et al. 2022
Note that the Meta team are not alone in this kind of giant data set effort. Google scientists in May unveiled a similar kind of massively multi-lingual effort, where they were able to scour the Web for over a million sentences in more than 200 languages and over 400,000 sentences in more than 400 languages.
Those training data sets are used to construct their neural net, NLLB-200. They start with the ubiquitous Transformer language model from Google that underlies most language translation today.
They use a 54-billion parameter Transformer, which is not huge (some modes are approaching a trillion parameters), but they make a key modification.
In between the individual layers of the network known as “attention heads,” the authors interleave conditional execution branches known as a sparsely gated mixture of exports. Basically, the experts can choose to turn off or on some of those 54-billion parameters when making predictions, so that the neural network can change its nature with each task.
“Sparsely Gated Mixture of Experts (MoE) models are a type of conditional compute models that activate a subset of model parameters per input, as opposed to dense models that activate all model parameters per input,” they explain. The value of the MoE, they explain, is that they “unlock significant representational capacity while maintaining the same inference and training efficiencies in terms of FLOPs [floating-point operations per second] as compared to the core dense architecture.”
The NLLB-200 network, right, inserts “mixture of experts” elements in between the standard attention blocks of the Transformer model, left. NLLB Team et al. 2022
(The authors even found a sweet spot for this approach: “Inserting MoE [mixture of experts] layers at an interval of every 4 Transformer blocks exhibits the best performance, in particular improving performance in very-low resource settings.”)
Along with the training set, the authors develop a new benchmark data set, FLORES-200, a high quality, many-to-many benchmark dataset that doubles the language coverage of a previous effort known as Flores- 101.” The data set is “created with professional human translators who translate the FLORES source dataset into the target languages and a separate group of independent translation reviewers who perform quality assessments of the human translations and provide translation feedback to the translators.”
Then, they test how the NLLB does on FLORES-200.
The results, as mentioned in the summary piece above, is an improvement of 44% in comparison to prior translation programs, as measured by common automated scores such as BLUE and chrF. They make extensive comparisons between different versions of those scores.
In addition to the automated scores, the authors had humans read translations and score them, and that’s where some cracks appear. Using a protocol first suggested in 2012 by Eneko Agirre and colleagues called “Semantic Textual Similarity,” the Meta team employ a variant called “XSTS,” which they introduced in a separate paper in May.
XSTS asks humans to rate translations on a scale of 1 to 5, with 1 being the worst, the two sentences have nothing to do with one another, and 5 being the best, they’re pretty much saying the same thing according to a person.
“In short, XSTS is a human evaluation protocol that focuses on meaning preservation far more than fluency,” they write.
“For low-resource languages, translations are usually of weaker quality, and so we focus far more on usable (meaning-preserving) translations, even if they are not fully fluent.”
The overall score is not bad when comparing how a baseline Transformer does for translations into and out of English and some other language, but they actually see worse results on one pair, from English into Greek:
Overall, NLLB-200 achieves an average XSTS score of 4.15 on out of English directions and 3.75 on into English directions. Compared to the baseline dense model, the performance of NLLB-200 is stronger. Certain directions have a significant difference, such as rus_Cyrl-tgk_Cyrl [Russian to Tagalog] and eng_Latn-gla_Latn [English to Scottish Gaelic]. We also notice that NLLB-200 performs better than the baseline on all tested directions with the only exception eng_Latn-ell_Grek [English to Greek] where performance was slightly worse.
But dig a little deeper and more cracks appear. Such a giant effort is a statistical enterprise, and with any statistical enterprise, more revealing than an average or a median is the distribution of scores.
On numerous language pairs, such as Armenian into English, and West Central Oromo into English, and Amharic, the most widely-used language in Ethiopia, translated into Armenian, and French translated into Wolof, the native language of the Wolof people of Senegal, and Hindi translated into Chhattisgarhi, a main language in the central India state of the same name, they find that little to no improvement over the baseline model.
Cracks appear where the human reviewers find some language pairs benefit very little or not at all from the NLLB-200 innovations, including language pairs such as Armenian translated into English and Amharic, the most widely-used language in Ethiopia, translated into Armenian. English translated into Greek turned out even worse than the baseline. NLLB Team et al. 2022
These isolated examples, which pop up amongst successes — a big improvement on Russian translated into Tagalog, a dominant language in the Philippines, for example — point to some deeper truth, which the scientists reflect on.
Without interpreting the human evaluations, the authors look at failure cases in the automated BLUE and chrF scores, and they hypothesize some limitations or shortcomings to their approach.
Either, they write, the language pairs with a lot of resources, including Greek, are not benefitting from the addition of the mixture of experts approach, or, their program starts to get so powerful, they are running into “over-fitting,” where a neural network has merely memorized some examples without forming a productive representation — meaning, it hasn’t “learned” anything at all, really.
As the authors put it,
High-resource pairs will likely have enough capacity in the 1.3 billion [parameter] dense model (given the size and nature of our ablation dataset) and will not benefit as much from the additional capacity of MoE models [and] As we increase computational cost per update, the propensity for low or very low-resource pairs to overfit increases thus causing performance to deteriorate.
The authors propose some steps that can be taken to mitigate over-fitting, such as a kind of “masking” of various inputs, and “conditional routing” in the mixture of experts.
Also: Watch out, GPT-3, here comes AI21’s ‘Jurassic’ language model
There are so many other details in the report about various experimental setups that it’s impossible to summarize all of the findings. Suffice it to say, the authors hope the open-source route — and $200,000 — will convince “the community to examine the current practices and improve where we fail, in a mission towards the north star goal of no language left behind.”
In particular, the curated translation data set, FLORES-200, is expensive to assemble using professional translators. “Extensions of Flores-200 to even more low-resource languages in the future may be difficult,” they observe.
Overall, they conclude, a multidisciplinary approach will be important,
Sharing NLLB with the larger scientific and research community will allow those with diverse expertise to contribute to the advancement of the project. In many ways, the composition of the NLLB effort speaks to the centrality of interdisciplinarity in shaping our vision. Machine translation lies at the intersection of technological, cultural, and societal development, and thus requires scholars with disparate training and standpoints to fully comprehend every angle. It is our hope in future iterations, NLLB continues to expand to include of scholars from fields underrepresented in the world of machine translation and AI, particularly those from humanities and social sciences background. More importantly, we hope that teams developing such initiatives would come from a wide range of race, gender, and cultural identities, much like the communities whose lives we seek to improve.
For all the latest Technology News Click Here
For the latest news and updates, follow us on Google News.
Denial of responsibility! NewsBit.us is an automatic aggregator around the global media. All the content are available free on Internet. We have just arranged it in one platform for educational purpose only. In each content, the hyperlink to the primary source is specified. All trademarks belong to their rightful owners, all materials to their authors. If you are the owner of the content and do not want us to publish your materials on our website, please contact us by email – [email protected]. The content will be deleted within 24 hours.